로컬 LLM 한국어 비교 — 내 PC에서 AI 챗봇 돌려본 솔직 후기 (2026)
로컬 LLM 한국어 성능, 직접 돌려보기 전까지는 감이 안 잡혔습니다. ChatGPT나 Claude 같은 유료 API를 쓰면 한국어를 유창하게 처리하는 건 당연한데, 문제는 비용입니다. 나만의 챗봇을 만들려고 하는데 API 호출마다 과금이 되니까, 테스트 단계에서부터 돈이 줄줄 새더라고요. “내 PC에서 무료로 돌릴 수 있는 LLM 중에 한국어 잘하는 게 없을까?” — 이 질문 하나로 시작된 삽질기를 공유합니다. Ollama 설치부터 5개 모델 비교, GPU vs CPU 속도 테스트까지 전부 직접 해본 결과입니다.
왜 로컬 LLM을 돌리려고 했나
처음 목표는 간단했습니다. 한국어를 유창하게 하는 나만의 AI 챗봇을 만드는 것. 고객 응대용이든, 사내 FAQ 봇이든, 아니면 그냥 재미로든 — 한국어로 자연스럽게 대화하는 봇이 필요했습니다.
OpenAI API나 Claude API를 쓰면 한국어 품질은 훌륭합니다. 하지만 개발 단계에서 이것저것 테스트하다 보면 API 호출이 수백, 수천 번 쌓이고, 비용이 눈덩이처럼 불어납니다. 프롬프트 하나 바꿀 때마다 돈이 나간다고 생각하면 실험을 마음대로 못 합니다.
그래서 방향을 바꿨습니다. 내 PC에서 무료로 돌릴 수 있는 오픈소스 LLM 중에서 한국어를 제대로 하는 모델을 찾아보기로 했습니다. 결론부터 말하면 꽤 쓸 만한 모델들이 있었고, 동시에 “아직은 유료 API를 완전히 대체하기는 어렵구나”라는 현실도 깨달았습니다.
Ollama 설치 — 로컬 LLM의 시작점
로컬 LLM 한국어 테스트를 하려면 먼저 LLM을 쉽게 돌릴 수 있는 도구가 필요합니다. 여러 가지가 있지만 가장 간편한 건 Ollama입니다. Docker처럼 명령어 한 줄로 모델을 다운로드하고 바로 실행할 수 있어서, 복잡한 환경 설정 없이 시작할 수 있습니다.
Mac에서 설치
ollama.com/download에서 macOS 버전을 다운로드하고 설치하면 끝입니다. 또는 Homebrew로 설치할 수도 있습니다.
brew install ollamaWindows에서 설치
같은 다운로드 페이지에서 Windows 버전을 받아서 설치합니다. 설치 후 PowerShell이나 CMD에서 바로 사용할 수 있습니다.
Linux에서 설치
curl -fsSL https://ollama.com/install.sh | sh설치 확인 및 첫 모델 실행
설치가 끝나면 터미널에서 아래 명령어로 확인합니다.
ollama --version버전이 뜨면 설치 성공입니다. 모델을 돌려보려면 이렇게 입력합니다.
ollama run gemma3처음 실행하면 모델을 다운로드하는데, 모델 크기에 따라 수 분이 걸릴 수 있습니다. 다운로드가 끝나면 바로 대화형 모드로 진입합니다. 한국어로 질문해보세요. 여기서부터가 진짜 시작입니다.
로컬 LLM 한국어 비교 — 5개 모델 직접 돌려본 후기
Ollama에서 돌릴 수 있는 모델 중 한국어 성능이 괜찮다고 알려진 모델들을 하나씩 테스트했습니다. 같은 질문(“한국의 사계절에 대해 설명해줘”, “이 코드의 버그를 찾아줘”, 일상 대화 등)을 던져보고 한국어 품질, 속도, 안정성을 비교했습니다.
① Gemma 3 (Google) — 가볍고 빠르고, 한국어도 꽤 한다
ollama run gemma3구글이 만든 오픈 모델입니다. 첫 인상은 “생각보다 한국어 잘하네?”였습니다. 문장이 자연스럽고, 간단한 질문에 대한 답변 품질이 유료 모델에 크게 뒤지지 않습니다. 무엇보다 가볍고 빠릅니다. 4B 모델 기준으로 VRAM을 많이 잡아먹지 않아서 일반 PC에서도 쾌적하게 돌아갑니다.
다만 복잡한 추론이나 긴 문맥을 요구하면 한계가 보입니다. 간단한 챗봇이나 FAQ 용도로는 가성비 최고입니다. 로컬 LLM 한국어 입문용으로 가장 추천하는 모델입니다.
② Qwen 2.5 (Alibaba) — 한국어 잘하는데… 갑자기 중국어가?
ollama run qwen2.5알리바바에서 만든 모델인데, 한국어 성능이 상당히 좋습니다. 문법도 정확하고 어휘력도 풍부해서 “이 정도면 쓸 만한데?”라는 생각이 들었습니다. 특히 코딩 관련 질문에서 답변 품질이 인상적이었습니다.
그런데 문제가 하나 있습니다. 많은 데이터를 처리하거나 긴 답변을 생성할 때 갑자기 중국어나 영어가 튀어나옵니다. 한국어로 잘 대답하다가 중간에 갑자기 “这个问题…”이 나오면 꽤 당혹스럽습니다. 짧은 대화에서는 괜찮은데, 긴 문맥에서 언어가 섞이는 현상이 간헐적으로 발생합니다. 중국어 학습 데이터가 압도적으로 많아서 생기는 현상으로 보입니다.
한국어 전용 챗봇에 쓰기에는 이 불안정성이 좀 걸립니다. 다국어 환경이라면 오히려 강점이 될 수도 있겠지만요.
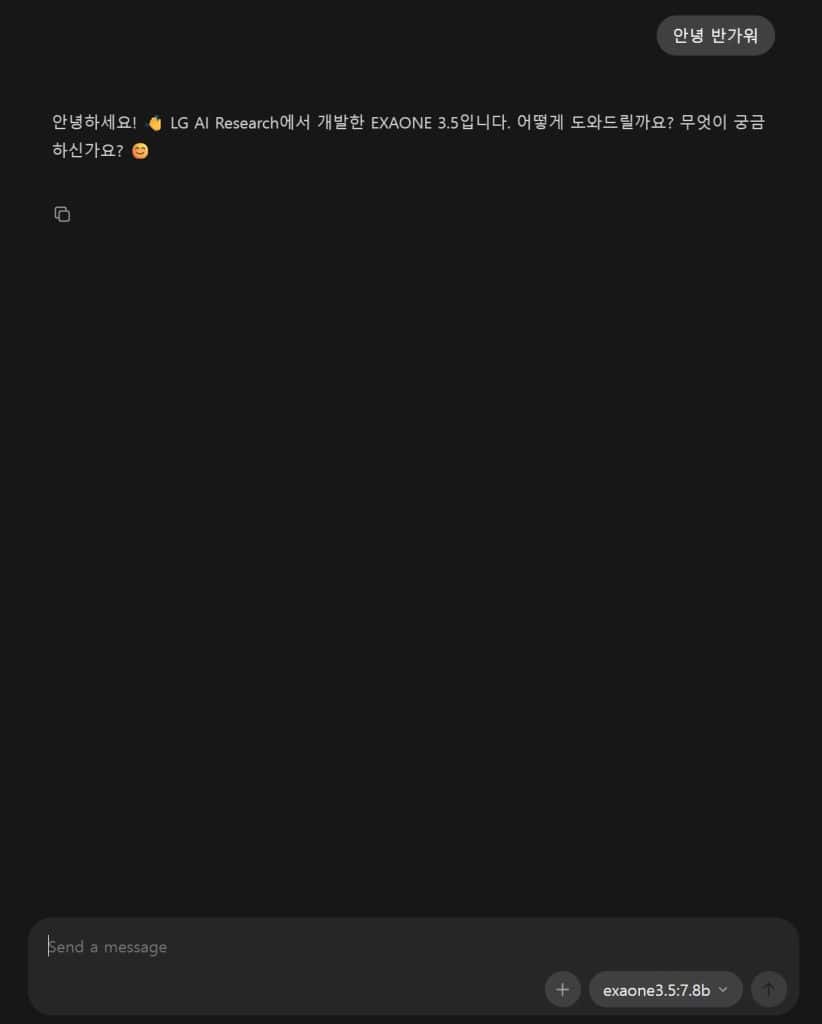
③ 엑사원 (LG AI Research) — 한국어 성능 최강, 하지만 상용화 불가
ollama run exaone3.5LG AI Research에서 만든 엑사원(EXAONE). 로컬 LLM 한국어 테스트에서 가장 인상적인 모델이었습니다. 결론부터 말하면, 오픈소스 로컬 모델 중에서 한국어를 가장 잘합니다.
답변의 자연스러움이 다른 모델과 확실히 차이가 납니다. 존댓말과 반말 전환이 자연스럽고, 한국어 특유의 어미 활용도 정확합니다. 속도도 생각보다 괜찮습니다. 7.8B 모델 기준으로 Gemma보다는 느리지만 충분히 실용적인 수준입니다.
아쉬운 점은 라이선스입니다. 엑사원은 연구 및 비상업적 용도로만 사용 가능하고, 상업적 서비스에 적용하려면 LG와 별도 협의가 필요합니다. 개인 프로젝트나 테스트 용도로는 자유롭게 쓸 수 있지만, 실제 서비스에 넣으려면 제약이 있습니다.
④ 야놀자 로제타 (Yanolja) — 한국어 특화, 근데 좀 느리다
ollama run yanolja/eeve야놀자에서 만든 한국어 특화 모델입니다. 이름부터 한국 기업이라 기대를 했는데, 한국어 품질은 확실히 좋습니다. 일상 대화, 고객 응대 시나리오에서 자연스러운 한국어를 구사합니다.
문제는 속도입니다. 같은 하드웨어에서 Gemma나 엑사원보다 토큰 생성 속도가 체감상 느린 편입니다. 짧은 답변은 괜찮은데, 긴 답변을 생성할 때 기다리는 시간이 좀 깁니다. 실시간 챗봇으로 쓰기에는 응답 지연이 신경 쓰일 수 있습니다.
⑤ Llama 3 8B (Meta) — 영어는 좋은데, 한국어는 글쎄
ollama run llama3Meta에서 만든 Llama 3 8B. 영어 기준으로는 성능이 정말 좋습니다. 하지만 한국어 챗봇을 만들겠다는 목적에서 보면 한국어 성능이 기대 이하입니다. 한국어로 질문해도 영어로 답하거나, 한국어 문법이 어색한 경우가 자주 발생합니다.
그리고 Llama 3에서 가장 뼈저리게 느낀 게 있습니다. GPU가 없으면 속도가 처참합니다.
GPU vs CPU — 속도 차이가 이 정도일 줄 몰랐다
로컬 LLM 한국어 테스트를 하면서 가장 충격받은 부분이 GPU와 CPU의 속도 차이입니다. 체감이 아니라 실제로 측정해봤습니다.
궁금해서 직접 실험을 해봤습니다. GPU 태스크를 kill하고 CPU만으로 같은 모델을 돌려본 겁니다.
# GPU 프로세스 확인
nvidia-smi
# Ollama를 CPU 전용으로 실행
CUDA_VISIBLE_DEVICES="" ollama run llama3결과는 충격적이었습니다. GPU로 돌렸을 때 초당 약 30~40 토큰이 생성되던 게, CPU만으로 돌리니 초당 3~4 토큰으로 떨어졌습니다. 약 10배 차이. 짧은 질문에 답하는 데도 체감상 10초 이상 걸리고, 긴 답변은 1분 넘게 기다려야 했습니다.
이 테스트로 깨달은 건, 로컬 LLM을 실용적으로 쓰려면 GPU는 선택이 아니라 필수라는 겁니다. 특히 Llama 3 같은 8B 이상 모델은 GPU 없이 돌리면 사실상 실시간 대화가 불가능합니다. Gemma 4B처럼 가벼운 모델은 CPU에서도 어느 정도 버틸 만하지만, 그래도 GPU 대비 체감 속도가 확연히 다릅니다.
집에 NVIDIA GPU가 있다면 로컬 LLM을 충분히 활용할 수 있습니다. 없다면 Gemma 같은 경량 모델을 쓰거나, 클라우드 GPU 서비스를 고려해보는 게 현실적입니다.
로컬 LLM 한국어 성능 비교 정리
| 모델 | 한국어 품질 | 속도 | 특징 | 추천 용도 |
|---|---|---|---|---|
| 엑사원 3.5 | ⭐⭐⭐⭐⭐ | 보통 | 한국어 최강, 비상업적 라이선스 | 개인 프로젝트, 연구 |
| Gemma 3 | ⭐⭐⭐⭐ | 빠름 | 가볍고 빠르고 한국어도 준수 | 입문, 간단한 챗봇 |
| Qwen 2.5 | ⭐⭐⭐⭐ | 보통 | 한국어 잘하지만 간헐적 중국어 혼입 | 다국어 환경 |
| 야놀자 로제타 | ⭐⭐⭐⭐ | 느림 | 한국어 특화, 토큰 생성 느린 편 | 한국어 전용 (비실시간) |
| Llama 3 8B | ⭐⭐⭐ | GPU 필수 | 영어 최고, 한국어는 부족 | 영어 위주 작업 |
결론 — 로컬 LLM 한국어, 지금 가장 잘하는 모델은
5개 모델을 직접 돌려본 결론입니다.
한국어 품질만 놓고 보면 엑사원이 압도적 1등입니다. LG AI Research가 한국어 데이터를 제대로 학습시킨 게 느껴질 정도로, 다른 오픈소스 모델과 한국어 자연스러움에서 확실한 격차가 있습니다. 상용화 제한만 없었으면 바로 서비스에 넣고 싶은 수준입니다.
실용성까지 따지면 Gemma 3가 가장 균형 잡혀 있습니다. 한국어가 엑사원만큼은 아니지만 충분히 쓸 만하고, 가볍고 빨라서 일반 PC에서도 쾌적하게 돌아갑니다. 로컬 LLM 한국어 입문자에게 가장 먼저 추천하는 모델입니다.
Qwen은 한국어 품질은 좋지만 언어 혼입 이슈가 있어서 한국어 전용 챗봇에는 좀 불안합니다. 야놀자 로제타는 한국어 특화라는 장점이 있지만 속도가 아쉽고, Llama 3은 한국어 목적이라면 우선순위에서 밀립니다.
그리고 어떤 모델을 선택하든, GPU는 거의 필수입니다. CPU만으로 돌리면 속도가 10배 느려져서 실시간 대화가 사실상 불가능합니다. 로컬 LLM을 제대로 활용하려면 NVIDIA GPU(최소 8GB VRAM)를 확보하는 게 첫 번째 투자입니다.
유료 API의 한국어 품질에는 아직 못 미치지만, 무료로 내 PC에서 돌린다는 점을 생각하면 놀라운 수준까지 왔습니다. 나만의 한국어 챗봇을 만들어보고 싶다면 Ollama 설치하고 Gemma부터 돌려보세요. AI 도구 전반이 궁금하다면 ChatGPT vs Claude vs Gemini 비교 글도 참고해보세요.